BTRONの舊漢字辭書をAnthyに移植
BTRONの舊漢字辭書をAnthyに移植
Puppy Linux 8.0の日本語入力システムとしてSCIM-Anthyを使ってますが使ひ勝手があまり良くありません。この手の話題になると大抵はGoogle出自のMozcにすれば快適云々との話になるのですが、私の場合は全く次元が違ひます。
見ての通り、私は舊漢字・舊假名使ひを常用してます。この舊漢字がLinuxでは變換出來ないわけですな。これはAnthyに限りません。Mozcを使っても同じ事です。Lubuntu環境ではMozcを使ってますが舊漢字は變換候補に出て來ません。
Windows環境であれば私の記憶する限りWindows95時代のOAKからは普通に舊漢字が變換候補として出て來ました。Japanist2003では若干扱ひが變更されましたが當たり前に舊漢字が出て來ます。
※OAKの頃は舊字體と新字體の混ざった單語が變換候補に出てましたがJapanist2003では舊字は舊字だけで統一する方針にした樣です。
これはOAK/Japanistが特殊なんでせうか?私が他のWindows用のIMEを使ふ機會は基本的にありません。インストール時のユーザ名には日本語を使ひませんし、インストール後はOAK/Japanistを標準にするので使ふ事は先づありません。時々勝手に切り變はっておバカな變換にイライラさせられる事はありますが(怒)。
世間で評判の高いATOKはDOS用のATOK8を持ってますが辭書サイズが巨大なくせに變換がおバカと言ふ意味不明な造りなのでLXやDOSモバに入れてはあるものの實際には使ってません。Windows用一太郎のCDが幾つかあるのでインストールすればWindows環境に導入は可能ですがWindows3.1の時に使ってみて印象が惡かったので入れる事は無いでせう(笑)。
※DOS用OAKとの比較に於いてです。DOSモバのNEC-AIよりはお利口さんです(^^;
ただ、DOS用はともかくポメラDM100に入ってるATOKでも舊字は變換候補に出て來ないしそれを出す爲の設定項目も見當たらないのでOAK/Japanistの樣に舊字を出せる方が珍しいのかも知れません。尚、OAKでもDOS用では舊字は出ません。Win3.1の頃は……憶えてない(^^;
LinuxにOAK/Japanistをインストール出來るなら問題は解決するのですが、生憎とそんな製品は存在しません。Wineを使へば出來るのかは不明ですがソフトの相性があったりWineのバージョンが新しければいいってものでもないので色々と面倒です。そこで私がBTRON上で使って來たVJE-Deltaのユーザ辭書をAnthyに移植しました。
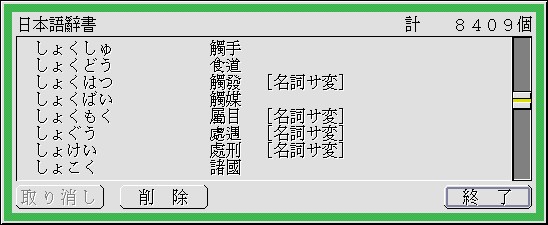
VJE-Deltaも標準では舊字が出ません。しかし私のユーザ辭書はBTRON上で使ひ續けた結果、多数の舊字が登録されてます。特に文字檢索で漢字を檢索すれば關聯情報として舊字も表示され、それをユーザ辭書畫面につかんでぽんすれば登録出來ると言ふ使ひ易さのお蔭で殆ど舊字體の爲に作ったユーザ辭書には8000語程が登録されてます。これを使へばAnthy(霞)でわざわざ登録し直す必要はありません。
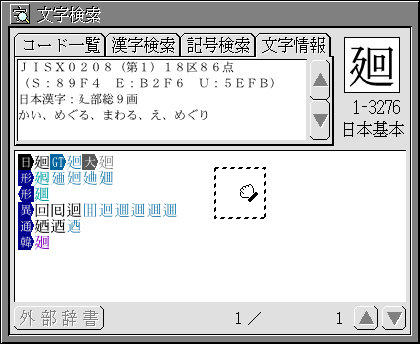
破線の四角は文字をつかんで移動させてる所です。BTRONでは文字であれ畫像であれファイルであれ同じ操作で移動させる樣に統一されてます。一般的なコピー&ペーストによる移動も可能です。
移植作業に當たって先づファイル變換を使ってユーザ辭書をWindows2000側へ持って行きました。BTRON上で作っただけにGT書體を含め他OSでは文字コードとして認識されない文字が多數含まれてるからです。文字セットをUTF-8にした上でWindows上で表示出來ない文字があればそれを削除する事でAnthyで登録可能な文字だけに整理出來ます。
この作業が面倒なんですな……語頭に&Txxxが來る語はソートして一括處理できますが語中・語尾に來るやつはソートも出來ず一つづつ目視で確認しないといけません。&Txxxなら檢索も出來るけど字によってはエディタ上の表示が「・」ですからね。コードはあるけどフォントが無いのかコードもフォントも無いのか區別がつきません。字によってはLinux上で表示させると?や豆腐になってました。それを目視で確認しながら修正……
移植に當たって面倒なのが品詞の分類。VJEとAnthyで分け方が違ふものがあります。VJEでは人名を姓と名で區別しますがAnthyでは區別しません。Anthyには會社名はありますが組織名ありません。「總督府」の樣な會社でない組織は一般名詞にするのか會社名の方に入れるのか……面倒なのでこの邊の分類はテキトーです(笑)。
ま、Linuxは文書データを扱ふメイン環境にはならないからいいでしょ。
移植の際に氣付いたのですが霞には動詞の一段活用がありません。區分が無ければ割愛するしかないか…と思ったのですが、調べてみるとcannaの分類に準據すればAnthyで認識する樣なのでテキストデータ上で一段活用を#KSに置換處理しました。これにより「ゐる」「率ゐる」などが登録できます。
しかし、ハ行四段活用に關しては全く存在しない樣です。今更古典表記を使ふ人はゐないとの前提なのでせう。この邊がやはりLinuxはプログラマ中心の世界なんだなぁと感じます。取り敢へずLinux上である程度の舊漢字を出せる樣になったので良しとしませう(^^;
cannaに準據した辭書を使ふ場合は注意が必要です。一段活用の樣に登録項目が霞に存在しない品詞はAhtny上で使へる事は使へるのですが品詞の項目が勝手に名詞に變更されてました。
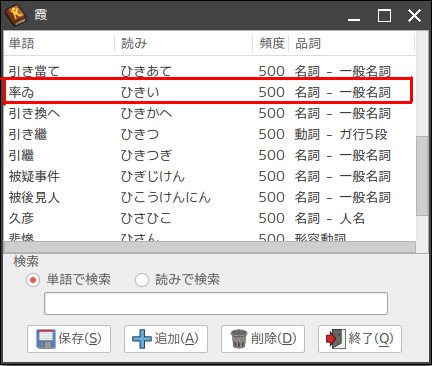
恐らく追加の登録を霞から行なった時に霞に無いものを書き換へたのだと思ひます。單語を追加で登録する場合は霞を使はずテキストデータとして直接書き込まないといけない樣です。その場合、ファイルの末尾に追加してソートされてないものは反映されませんでした。つまりその單語が順番的に何處に來るかを搜して書き足せって事か……
そもそもPuppy8.0の霞では日本語入力が出來ないので霞側から追加したいならテキストエディタに下書きしてコピペするしか無いわけですが(^^;
う〜む、使ひにくいなぁ…
■追記■
とある方からBTRON用の舊漢字辭書が欲しいとの要望があったので公開しました。その中におまけとしてAnthy用のも入れました。こちらのダウンロード用のページに置いてあります。
前ニ戻ル
應援バナー(^^;
